Assignment 2
Before working on this assignment please read these instructions fully. In the submission area, you will notice that you can click the link to Preview the Grading for each step of the assignment. This is the criteria that will be used for peer grading. Please familiarize yourself with the criteria before beginning the assignment.
An NOAA dataset has been stored in the file data/C2A2_data/BinnedCsvs_d400/fb441e62df2d58994928907a91895ec62c2c42e6cd075c2700843b89.csv. This is the dataset to use for this assignment. Note: The data for this assignment comes from a subset of The National Centers for Environmental Information (NCEI) Daily Global Historical Climatology Network (GHCN-Daily). The GHCN-Daily is comprised of daily climate records from thousands of land surface stations across the globe.
Each row in the assignment datafile corresponds to a single observation.
The following variables are provided to you:
id : station identification code date : date in YYYY-MM-DD format (e.g. 2012-01-24 = January 24, 2012) element : indicator of element type TMAX : Maximum temperature (tenths of degrees C) TMIN : Minimum temperature (tenths of degrees C) value : data value for element (tenths of degrees C) For this assignment, you must:
Read the documentation and familiarize yourself with the dataset, then write some python code which returns a line graph of the record high and record low temperatures by day of the year over the period 2005-2014. The area between the record high and record low temperatures for each day should be shaded. Overlay a scatter of the 2015 data for any points (highs and lows) for which the ten year record (2005-2014) record high or record low was broken in 2015. Watch out for leap days (i.e. February 29th), it is reasonable to remove these points from the dataset for the purpose of this visualization. Make the visual nice! Leverage principles from the first module in this course when developing your solution. Consider issues such as legends, labels, and chart junk. The data you have been given is near Ann Arbor, Michigan, United States, and the stations the data comes from are shown on the map below. ____________________
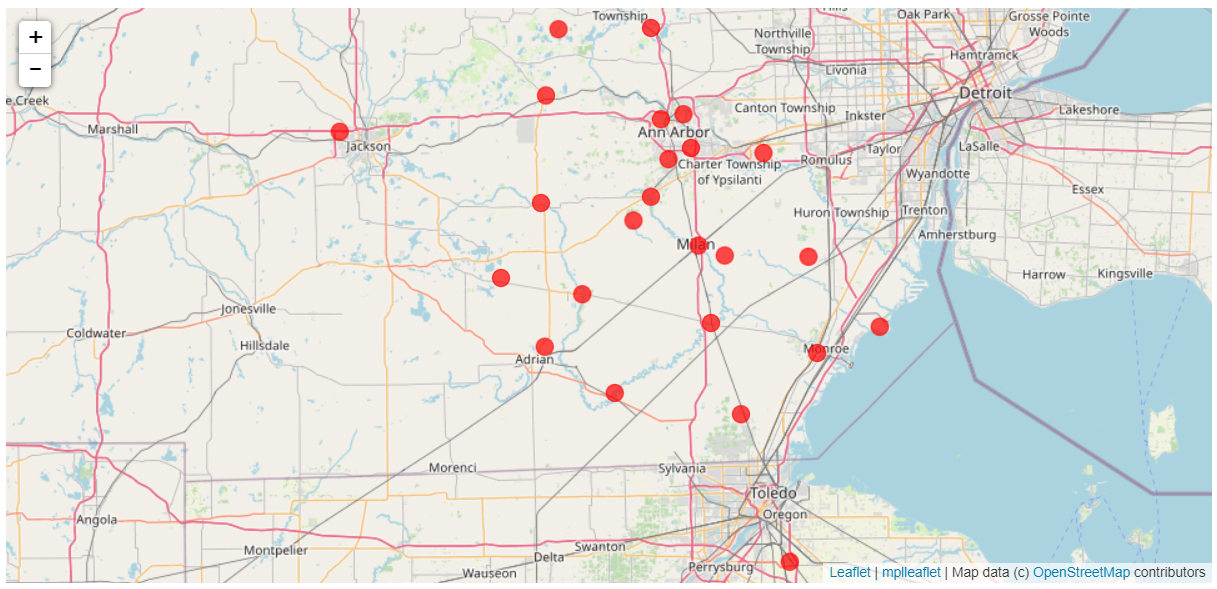
Visualizing the location
I imported the required libaries.
import matplotlib.pyplot as plt
import mplleaflet
import pandas as pd
import numpy as np
Let’s load the data and check out the locations!
def leaflet_plot_stations(binsize, hashid):
df = pd.read_csv('data/C2A2_data/BinSize_d{}.csv'.format(binsize))
station_locations_by_hash = df[df['hash'] == hashid]
lons = station_locations_by_hash['LONGITUDE'].tolist()
lats = station_locations_by_hash['LATITUDE'].tolist()
plt.figure(figsize=(8,8))
plt.scatter(lons, lats, c='r', alpha=0.7, s=200)
return mplleaflet.display()
leaflet_plot_stations(400,'fb441e62df2d58994928907a91895ec62c2c42e6cd075c2700843b89')
Setting up the temperature data
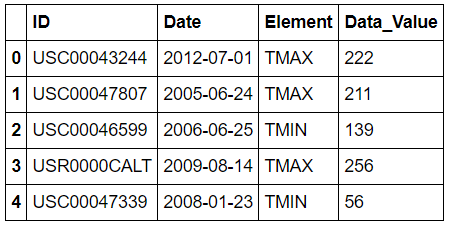
Let’s view the data.
# Setting matplotlib inline
get_ipython().magic('matplotlib inline')
df = pd.read_csv('data/C2A2_data/BinnedCsvs_d400/fd403b3054061a52e5c4a08dadc245bc6e1b0adabbf12a9eadba68e8.csv')
df.head()
I sorted the data and split it on year and month.
df = df.sort_values(by=['ID','Date'])
# Date to string to pull month and year
df['Date'] = df['Date'].astype(str)
#Skipping leap year day
df = df[~df.Date.str.contains('02-29')]
df['Year'], df['Month'] = zip(*df['Date'].apply(lambda x: (x[:4], x[5:])))
Finding High and Low Temps
I found the annual low and high temps.
low = df[(df['Element'] == 'TMIN') & (df['Year'] < '2015')].groupby(['Month']).aggregate({'Data_Value':np.min})
high = df[(df['Element'] == 'TMAX') & (df['Year'] < '2015')].groupby(['Month']).aggregate({'Data_Value':np.max})
I found the low and high temps in 2015.
low_2015 = df[(df['Element'] == 'TMIN') & (df['Year'] == '2015')].groupby(['Month']).aggregate({'Data_Value':np.min})
high_2015 = df[(df['Element'] == 'TMAX') & (df['Year'] == '2015')].groupby(['Month']).aggregate({'Data_Value':np.max})
I calculated daily temps in 2015 that were new high or low temps.
new_low = np.where(low_2015['Data_Value'] < low['Data_Value'])
new_high = np.where(high_2015['Data_Value'] > high['Data_Value'])
Creating the visualization
I made the data usable in my visualization.
lows = low.reset_index()
lows = lows.drop(['Month'], axis=1)
lows = np.array(lows)
low_new = lows.flatten()
highs = high.reset_index()
highs = highs.drop(['Month'], axis=1)
highs = np.array(highs)
high_new = highs.flatten()
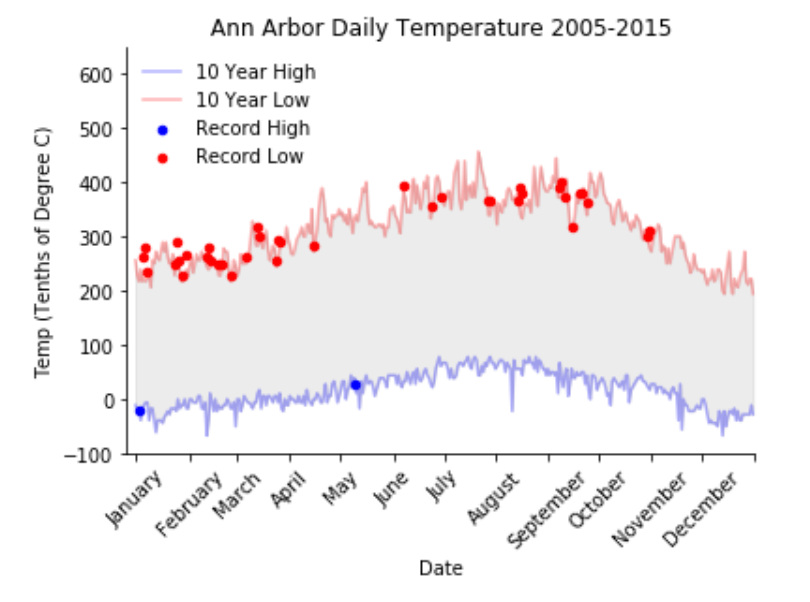
Lastly, I graphed my data!
plt.figure()
plt.plot(low_new, '-', color = 'b', alpha = 0.3)
plt.plot(high_new, '-', color = 'r', alpha = 0.3)
plt.gca().fill_between(range(len(low_new)), low_new, high_new,
color='grey',
alpha=0.15, label = '_nolegend_')
plt.xlabel('Date')
plt.ylabel('Temp (Tenths of Degree C)')
plt.title('Ann Arbor Daily Temperature 2005-2015')
plt.gca().axis([-5,365, -100, 650])
axes = plt.axes()
axes.set_xticks([0,32,60,91,121, 152, 182, 212,243,273, 304, 334, 365])
axes.set_xticklabels(['January','February', 'March','April','May', 'June', 'July', 'August', 'September', 'October', 'November', 'December'])
plt.xticks(rotation=45)
plt.gca().spines['top'].set_visible(False)
plt.gca().spines['right'].set_visible(False)
plt.scatter(new_low, low_2015.iloc[new_low], s=20, c='blue')
plt.scatter(new_high, high_2015.iloc[new_high], s=20, c='red')
plt.legend(['10 Year High', '10 Year Low', 'Record High', 'Record Low'], frameon=False, loc = 0)